다시 생각하는 오라클 데이터베이스 운영
Overview
DBA는 보수적이라는 인식이 흔히 있다. 새로운 시도를 하다가 큰 문제가 발생할 수 있어서 기존 방식을 변경하기가 쉽지 않기 때문이다. 그래서 익숙한 것이 후임자에게 이어지는 것이 반복되고 나중엔 이유는 모르지만 어쨌든 기존 방식을 유지하게 된다.
해외에서도 이런 문제에 대한 언급1을 찾을 수 있으니 국내에만 국한된 문제가 아닌 것 같다. 이 글에서 그런 것들 중 몇가지 사례를 들고 대안을 제시해 보려고 한다.
이 포스트는 2012년에 월간 마이크로소프트웨어에 기고한 글을 다듬은 것이다
Index-Organized Table (IOT)의 적극적인 사용
Point:
- IOT로 손쉽게 극적인 성능 개선 효과를 볼 수 있다
- IOT에 적합한 데이터는 생각보다 흔하다
- DML 비중이 많아도 IOT를 쓰는데 문제가 없다
IOT 는 인덱스 구조와 유사한 테이블 형태이다. IOT의 개념에 대해서는 독자가 이미 알고 있거나, 다른 곳에서 잘 정리된 설명을 쉽게 찾을 수 있을 것이니 여기선 자세한 설명보다 그 유용성을 강조하려고 한다.
아래 <그림1>은 지난 2005년에 IOT로 성능 개선 효과를 본 사례이다.
<그림1> 친구 목록 데이터에 대해 IOT 적용 전후 CPU 사용량 비교
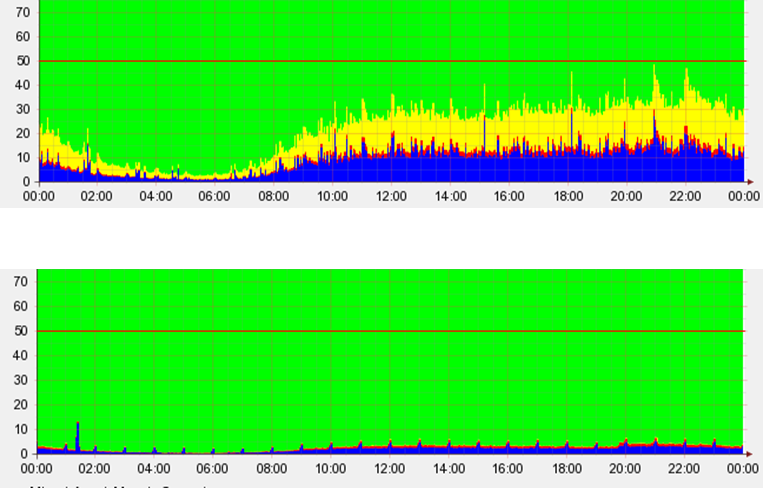
하지만 IOT는 아직 소극적으로 사용되는 경우가 많은데, 효과에 대해서는 덜 알려지고 약점은 실제보다 부각되었기 때문이다
널리 알려진 IOT의 단점은 DML에 취약하다는 것이지만 정말 그럴까? 생각해보면 IOT에 DML을 실행할 때 발생하는 부하는 인덱스가 있는 일반 테이블 (heap organized table)과 별 차이가 없다. 결국 인덱스가 있는 테이블을 별 문제없이 사용할 수 있다면 IOT 역시 잘 사용할 수 있다. 나는 IOT의 활용 여부를 판단할 때 DML비중을 고려하지 않지만 성능 문제가 발생한 경우는 없다.
IOT에 대한 걱정을 덜 수 있는 좋은 비교 대상이 있다. MySQL에서 InnoDB 엔진을 사용하는 테이블들이 IOT와 유사한 구조로 되어 있다. MySQL에선 온라인 백업과 트랜잭션을 지원하기 위해 모든 테이블을 InnoDB 로 만드는 경우도 흔하다.
그럼 IOT는 어떤 곳에 사용해야 성능 개선 효과를 볼까? 목록 형식의 데이터를 조회하는 경우에 적합하다. 사용자의 친구목록 조회, 게시판 별 게시글 조회, 댓글 조회 같은 것인데 모두 흔한 것들이다.
쿼리 튜닝 다음으로 눈에 띄는 성능 개선 효과를 기대할 수 있는 것이 IOT의 적절한 사용이라고 생각한다. IOT는 그것을 사용해서 효과를 볼 수 있는 대상이라면 적극적으로 사용하는 것이 좋다.
Note: IOT는 secondary index로 인한 비효율 등이 문제가 될 수 있다. IOT를 제대로 활용하려면 서비스 적용 전에 그 것의 특징에 대해서 정확히 알고 있어야 한다.
스토리지 성능과 Storage Area Network (SAN)
Point:
- 스토리지의 I/O 성능은 장착된 개별 디스크의 성능과 수에 단순하게 비례한다
- SAN은 비용을 낮추기 위한 기술이다
스토리지 시스템의 성능은 그것에 장착된 디스크의 성능과 개수에 좌우된다. 고가의 스토리지 제품과 중저가 제품의 가장 중요한 차이는 장착 가능한 디스크의 개수이다. 하지만 디스크 개수가 같다면 스토리지의 I/O성능은 기본적으로 동일하다.
데이터는 계속 늘어나게 마련이고 만약 그에 따라 고가 제품으로 교체해야 한다면 비용 부담이 클 것이다.
저비용으로 스토리지 확장 문제를 해결해주는 기술이 SAN (Storage Area Network) 이다. SAN 스위치를 중심으로 스토리지들과 그것을 사용할 호스트들의 네트워크를 구성해 각 호스트들이 필요한 만큼의 저장 공간을 여러 스토리지로부터 얻을 수 있다. ‘SAN은 비싸다’ 는 오해와 달리 비용을 줄이고 높은 확장성을 얻기 위해 만들어진 것이다. 저가의 스토리지들을 필요할 때마다 붙여나가는 방식으로 시스템을 손쉽게 확장할 수 있다.
이와 같이 스토리지의 확장 문제는 이미 오래 전에 SAN 기술로 해결이 되었지만 여전히 장점이 충분히 알려지지 않고 있는데, 그것은 스토리지 벤더의 입장과 관련이 있다. SAN을 기본 취지에 맞게 활용해 비용이 줄어들면 벤더의 수익도 줄어든다. 그러니 벤더 측에서 그 장점을 고객에게 적극적으로 알리지 않는 것도 한편으론 이해할 만한 일이다. 어떤 벤더에선 나에게 성능을 위해 SAN 스위치를 사용하지 말것을 권한 경우도 있다. SAN의 확장성의 핵심 구성 요소가 스위치인데도 그렇게 얘기가 된다.
그리고, 특정 벤더에 종속되지 않는 시스템을 유지하기 원한다면 특정 벤더의 복제 솔루션은 사용하지 않는 것이 좋다. Oracle의 RMAN과 Data Guard 기능을 잘 활용하면 충분히 효율적인 백업,복제를 구현하는 것이 가능하다.
RMAN으로 백업
Point:
- Oracle 10g 이후의 RMAN은 훌륭한 백업 도구이다
적어도 10g 이후에는 RMAN을 백업/복구 도구로 사용해도 전혀 문제가 없다.
외부 솔루션을 이용해서 user managed backup 방식을 사용하면서 RMAN 사용을 주저하는 이유는 아래와 같다.
- RMAN에 대한 신뢰 부족
- DBMS가 실행되는 호스트 시스템에서 process로 실행되는 in-bound 방식이 DBMS 성능에 미칠 악영향에 대한 우려
첫 번째는 과거에는 문제가 되었으나 이제는 해소된 것이고 두 번째는 시스템이 적절하게 셋업되어 있으면 문제가 없다. 여기서 적절한 시스템 셋업이란 아래를 갖춘 것이다.
- redo log 파일과 control 파일이 저장되는 디스크를 데이터,백업이 저장되는 디스크와 물리적으로 분리해서 서로 I/O 간섭이 없게 한다
- 충분히 높은 buffer cache hit rate
- 합리적인 스토리지 투자로 괜찮은 수준의 physical I/O 성능이 확보됨
이런 조건에서는 설령 피크 시간에 백업을 실행하더라도 문제가 없다. 원활한 서비스를 위해 필요한 것들이니 만약 백업 실행이 서비스에 영향을 미친다면 시스템이 제대로 셋업된 것인지 점검할 필요가 있다.
그럼 잘 구성된 시스템에서 왜 백업이 DB성능에 영향을 미치지 않는 지 더 알아보자. 백업 작업은 데이터가 저장된 디스크 장치의 physical I/O 성능을 일정하게 저해할 것이다.
하지만
- redo log 파일은 백업 대상이 아니므로 데이터/백업과 물리적으로 독립되어 있기만 하면 DML과 트랜잭션 실행이 지연되지 않는다
- SELECT는 그것이 대부분 logical reads로 커버되는 환경이라면 physical read가 약간 느려져도 눈에 띄는 영향이 없어야 한다
- DBWR가 담당하는 physical write는 백업에 의해 영향을 받지만 백그라운드에서 일어나는 프로세스 이므로 사용자가 느끼는 성능과는 관련이 없다
즉 RMAN을 사용해도 성능상 걱정할 것이 없으며 RMAN은 아래와 같은 장점이 있다.
- 별도의 솔루션을 구매하지 않아도 된다.
- 백업에 대한 DBA의 이해도가 높아진다. 외부 솔루션을 사용하면 업무 담당자 이외에는 전체 백업프로세스를 이해하기 어렵다
- RMAN repository에 백업과 관련된 세세한 메타데이터를 기록해서 사용자 작업을 쉽고 단순하게 한다.
아직 RMAN을 사용하고 있지 않은 독자가 쉽게 실행해 볼 수 있도록 사용 중인 스크립트를 공유한다.
1rman target / <<_EOF | tee logs/backup.log.`date +%m%d`
2RECOVER COPY OF DATABASE with TAG "whole_db_copy" UNTIL TIME 'trunc(SYSDATE)-7';
3DELETE NOPROMPT OBSOLETE;
4BACKUP INCREMENTAL LEVEL 1
5 FOR RECOVER OF COPY WITH TAG "whole_db_copy"
6 DATABASE;
7_EOF
이 스크립트는 10g 이상에서 DB_RECOVERY_FILE_DEST 파라미터를 설정해 놓고 실행하면 된다. 짧은 내용이지만 incremental backup을 실행하고 최근 7일간 원하는 시점으로 point-in-time recovery가 가능하며, 필요 없는 archive log 만을 알아서 지우는 등 효율적인 백업을 구현할 수 있다. 각 명령어에 대한 자세한 설명은 공식 매뉴얼을 참고하면 된다.
Note: Oracle 10g 기준으로 Backup and Recovery Basics 매뉴얼의 4.4 RMAN Incremental Backups에 나와있다.
날짜 데이터에 DATE 타입 사용
Point:
- 날짜/시각 데이터는 DATE 타입에 저장해야 한다.
날짜 데이터를 위한 DATE 타입이 있지만 VARCHAR2 형식으로 저장하는 경우가 많다. VARCHAR2를 다루는 것이 이미 익숙하고 이것으로도 날짜 데이터를 표현하는데 문제가 없다고 보기 때문인데 그렇다면 숫자는 왜 NUMBER에 저장할까? 날짜에 DATE를 써야 하는 이유는 숫자에 NUMBER를 써야 하는 이유와 같다.
DATE 타입의 장점은 아래처럼 정리할 수 있다.
- 저장공간 절약
- 무결성 보장
- 연산의 편리함과 SQL문의 간결함
- Optimizer에 더 풍부한 정보를 제공
1. 저장공간 절약
VARCHAR2로 저장하면 작게 잡아도 14 바이트가 필요하지만 DATE는 7 바이트면 된다.
2. 무결성 보장. 데이터와 포맷의 분리
날짜 형식이 아닌 엉뚱한 데이터가 입력되거나 여러 형식의 날짜 포맷이 뒤섞이는 것을 막을 수 있다. VARCHAR2를 사용하면 특정한 날짜 포맷을 표준으로 정하고 항상 그 형식으로 사용해야 하는데, 이 약속을 지키기가 쉽지 않다. 여러 경로로 실행되는 SQL문을 일일이 통제한다는 것이 사실상 불가능하기 때문이다. 일정 시간이 지나면 결국 여러 포맷의 데이터가 섞이게 된다. 그리고 컬럼마다 서로 다른 날짜 포맷을 사용한다면 테이블에 INSERT할 때마다 어떤 포맷인지 확인해야 해서 번거롭다. 결국 VARCHAR2에 저장하려면 꼼꼼한 관리가 필요하다. 그러니 애초에 그런 수고가 필요 없는 방법을 사용하자.
3. 연산의 편리함과 SQL문의 간결함
전체적으로 SQL문이 간결해진다. 예를 들면, 날짜 데이터가 INSERT되거나 비교의 기준으로 sysdate 가 사용되는 경우가 많은데 이럴 때 DATE 라면 아래처럼 sysdate를 그대로 사용하면 된다.
1INSERT INTO T (DATE_DATE) VALUES (sysdate)
그렇지 않으면 아래처럼 TO_CHAR()로 일일이 변환을 해야 한다.
1INSERT INTO T (STR_DATE) VALUES (TO_CHAR(sysdate,'YYYYMMDDHH24MISS'))
DATE 연산에서 간결함의 차이가 잘 보이는데, 예를 들어 어떤 날짜보다 하루 뒤의 값을 구하려면 DATE 는 아래처럼 단순하다.
1DATE_DATE + 1
VARCHAR2는 깔끔하지 않은 문자열 연산을 하거나, DATE 타입으로 변환했다가 다시 VARCHAR2로 변환해야 한다.
1TO_CHAR(TO_DATE(STR_DATE,'YYYYMMDDHH24MISS') + 1 , 'YYYYMMDDHH24MISS')
이런 연산은 자주 하는 것이라 누적되면 SQL문의 가독성이 나빠진다.
4. Optimizer에 더 많은 정보를 제공
Oracle optimizer 는 실행 계획을 만들 때 DATE 타입의 특성을 이해하고 활용한다. 2012년 1월 1일 과 2012년 1월 3일 사이에 들어갈 수 있는 날짜는 1월 2일 하루 뿐이지만 ‘20120101’ 과 ‘20120103’ 사이에 분포하는 문자열 값은 훨씬 많다. 즉 날짜/시각을 DATE로 저장하면 optimizer에 더 풍부한 정보를 제공할 수 있다.
DATE 타입을 더 편리하게 쓰는 팁
DATE를 사용하면 형 변환을 위해 to_date() 와 to_char()를 매번 실행해야 해서 번거로울 것 같지만 알고 보면 그렇지 않다. 우선, NLS_DATE_FORMAT 파라미터로 시스템 디폴트 날짜 포맷을 지정할 수 있다.
1ALTER SYSTEM SET NLS_DATE_FORMAT = 'YYYY-MM-DD HH24:MI:SS'
기본적으로 to_date() 와 to_char() 는 두 번째 인자로 날짜 포맷을 받는데 이것을 생략하면 NLS_DATE_FORMAT의 값이 디폴트로 사용된다. 그리고 이 함수들은 형 변환이 필요할 때 암묵적으로 호출되므로 이 함수들을 명시적으로 쓸 필요가 없다.
그리고 값을 입력할 때, 지정된 날짜 포맷과 정확히 일치하지 않더라도 비슷한 형태면 대부분 인식이 된다. 예를 들어 아래처럼 테이블을 만들고 입력할 때
1CREATE TABLE DATE_TEST (D DATE);
정석은 아래와 같지만
1INSERT INTO DATE_TEST VALUES(TO_DATE('2008-01-01 10:00:01','YYYY-MM-DD HH24:MI:SS'))
아래처럼 해도 성공한다.
1INSERT INTO DATE_TEST VALUES ('2008-01-01 10:00:01');
2INSERT INTO DATE_TEST VALUES ('20080101100001');
3INSERT INTO DATE_TEST VALUES ('2008:01:01 10');
데이터의 값은 포맷과는 독립되어 있기 때문에 표현이 달라도 실제로 저장되는 값에는 차이가 없다.
1SELECT * FROM DATE_TEST;
2D
3-------------------
42008-01-01 10:00:01
52008-01-01 10:00:01
62008-01-01 10:00:00
72008-01-01 10:00:01
단순한 테이블스페이스 구성
Point:
- 인덱스와 테이블을 별도의 테이블스페이스에 저장할 필요가 없다
- 스키마 당 하나의 테이블스페이스를 만들면 편리하다.
테이블스페이스를 지나치게 잘게 쪼개거나 테이블,인덱스용 테이블스페이스를 분리할 필요가 없다. 테이블과 인덱스를 함께 저장하고 크기도 크게 만들자.
스키마 단위로 하나의 테이블스페이스를 할당하고 그 스키마의 디폴트 테이블스페이스로 지정하는 것을 권한다. 이렇게 하면 테이블이나 인덱스를 어떤 테이블스페이스에 넣어야 할지 남은 용량을 확인하면서 DDL에 일일이 지정하지 않아도 된다. 전체적인 테이블스페이스 수가 줄어서 관리가 간편해진다. 이런 단순한 규칙이면 개발환경 DB와 서비스DB의 테이블스페이스 구성을 동일하게 유지할 수 있게 되고 그에 따라 개발 환경 DB에서 사용한 DDL을 그대로 서비스 환경 DB에도 사용할 수 있다.
테이블스페이스를 스키마 단위로는 분리하는 이유는, 테이블스페이스 단위의 복구(recovery) 나 스키마 단위로 다른 인스턴스로 이동할 때 Transportable Tablespace 기능 사용을 대비한 것이다.
테이블스페이스의 크기는 평상시 성능과는 관계가 없지만 테이블스페이스 단위의 복구를 해야 할 경우엔 복구 시간이 그것에 비례한다. 나는 스키마 당 한 개의 테이블스페이스를 기본 원칙으로 하되, 최대 용량은 1TB 로 제한하는 방식을 쓰고 있다.
100GB 크기의 테이블스페이스 하나를 만드는 것에 비해 10GB 짜리 10개를 만들었을 때 성능 상 유리한 점이 없고 테이블과 인덱스를 별도의 테이블스페이스에 분리 저장해서 얻을 수 있는 이점 역시 없다.
테이블스페이스는 데이터를 논리적으로 분리해서 저장하는 단위이기 때문에 I/O 성능과는 직접적인 관계가 없다
-
Thomas Kyte의 Effective Oracle by Design 은 이런 것들을 myths 라고 표현하며 여러 사례를 알려준다. ↩︎