[Kubernetes] Cluster Autocaler의 scale-down 튜닝
Cluster Autoscaler(CA)는 클러스터의 노드 개수를 적절하게 유지하는 역할을 한다.
새로 생성된 pod이 실행될 노드가 없어 Pending 상태라면 노드를 생성하고,
반대로 필요한 리소스에 비해 노드 수가 불필요하게 많다면 한가한 노드를 없애서 리소스 집적도를 높이는 scale-down을 한다.
CA가 특정 노드를 없애려면 몇가지 제약 조건에 해당하지 않아야 하는데, 이런 제약 조건 때문에 scale-down 효율이 떨어지면 불필요한 비용을 지출하게 될 수 있다.
CA의 scale-down 효율을 높여서 비용 절감에 효과를 본 방법을 정리했다. 요약하면 아래와 같다.
- --skip-nodes-with-local-storage 옵션을 false로 설정
- --scale-down-utilization-threshold 옵션값 올리기
- application의 PodDisruptionBudget(PDB)가 scale-down을 막고 있는 경우 PDB 수정
- kube-system namespace에 속한 pod에 PodDisruptionBudget을 설정 (kube-dns 등)
Cluster Autoscaler의 scale-down 조건
Clusster Autosacler FAQ 문서에 잘 기술되어 있다.
노드에 아래 조건에 해당하는 pod이 있으면 CA가 노드를 제거할 수 없다. 이 포스트의 맥락에 해당하는 것만 추렸다.
- 로컬 스토리지를 사용하는 경우
- PodDisruptionBudget에 의해 pod을 종료할 수 없는 경우
- kube-system namespace에 속한 pod. 적절한 PodDisruptionBudget 설정을 해주면 이 제한을 풀 수 있다.
현재 노드 개수가 적절한지 확인하는 방법
우선 현재 scale-down을 충분히 효율적으로 하고 있는지 확인해야 한다. 노드의 ‘리소스 활용률’ 이 충분히 높아야 하는데, 아래처럼 계산할 수 있다.
리소스 활용률 = (노드에서 실행되는 컨테이너들의 resource request 합)/(노드의 resource capacity)
컨테이너에서 실행되는 프로세스들이 실제 사용하는 수치가 아니라 컨테이너의 resource 설정에서 cpu나 memory request 값을 따지는 것이다.
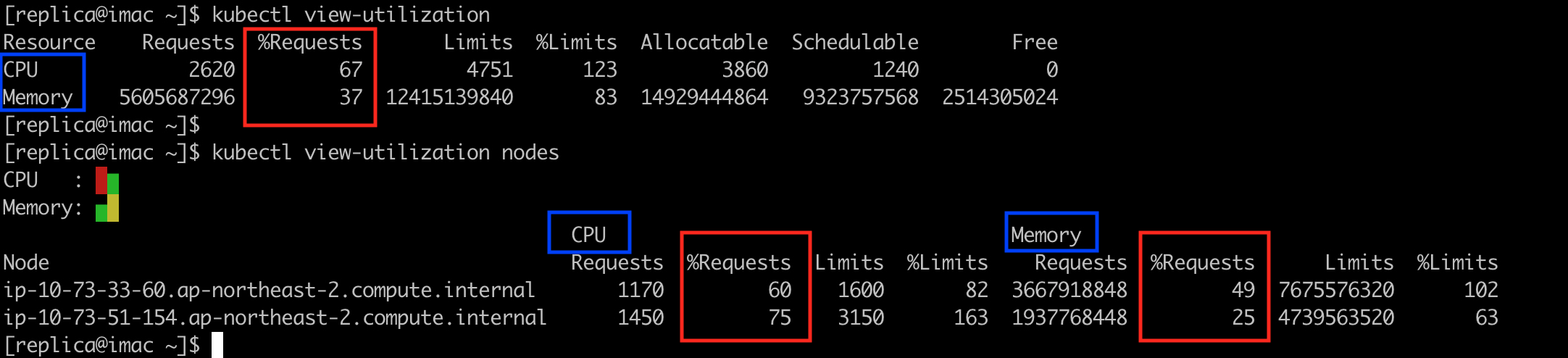
노드별 리스스 활용률은 kubectl로 대략 파악할 수 있다.
1$ kubectl describe nodes | grep Resource --after=3
kubectl에 view-utilization plugin을 설치하면 더 쉽게 확인할 수 있다.
1$ kubectl view-utilization # 클러스터 전체 현황
2$ kubectl view-utilization nodes # 노드별 현황
아래는 kubectl view-utilization 명령의 실행 결과 예시이다.
제대로 관리하려면 결국 Prometheus 같은 모니터링 시스템의 관리 대상에 포함해야 한다.
kube-state-metrics가 제공하는 metric을 조회하는 Prometheus 쿼리는 아래와 같다.
클러스터 CPU 리소스 활용률 평균: sum (kube_pod_container_resource_requests{resource="cpu"}) / sum (kube_node_status_capacity{resource="cpu"} )
클러스터 메모리 리소스 활용률 평균: sum (kube_pod_container_resource_requests{resource="memory"}) / sum (kube_node_status_capacity{resource="memory"} )
CA의 로그로 scale-down을 하지 않는 이유 확인
CA는 특정 노드를 scale-down 대상으로 취급하지 않는지 이유를 로그로 자세히 알려준다. 아래 명령으로 확인할 수 있다.
1$ kubectl logs -f -n kube-system $(kubectl get pod -o Name -n kube-system -l app.kubernetes.io/instance=cluster-autoscaler)
로그의 예는 아래와 같다.
1I1119 16:13:22.567346 1 cluster.go:148] Fast evaluation: ip-10-76-141-178.ap-northeast-2.compute.internal for removal
2I1119 16:13:22.567357 1 cluster.go:169] Fast evaluation: node ip-10-76-141-178.ap-northeast-2.compute.internal cannot be removed: pod with local storage present: istiod-1-10-4-6c66f78678-7wl5r
3...
4
5I1119 16:18:57.113554 1 scale_down.go:443] Node ip-10-91-71-213.ap-northeast-2.compute.internal is not suitable for removal - cpu utilization too big (0.917098)
6I1119 16:18:57.113607 1 scale_down.go:443] Node ip-10-91-70-122.ap-northeast-2.compute.internal is not suitable for removal - memory utilization too big (0.962740)
튜닝 방법
1. CA의 skip-nodes-with-local-storage 옵션을 false로 설정
Helm chart의 디폴트 값은 true지만 항상 false로 설정하는 것을 권장한다. 경우에 따라 비용 절감 효과가 상당히 클 수도 있다.
Helm chart를 설치할 때 values.yaml을 아래처럼 설정하면 된다.
1extraArgs:
2 skip-nodes-with-local-storage: false
이 옵션이 true이면 emptyDir이나 hostPath를 volume으로 사용하는 pod이 있는 노드를 scale-down 대상에서 제외한다.
노드가 없어져서 데이터가 유실되는 경우를 막기 true로 설정하는 것이 일견 자연스러워 보이지만 그렇지 않다. 보존해야 하는 데이터라면 애초에 로컬 스토리지를 사용하면 안된다. AWS라면 persistentVolumeClaim을 통해 EBS volume 등에 데이터를 저장해야 한다1.
그런데 이미 모든 app들이 로컬 스토리지에 ‘보존이 필요한 데이터’를 저장하지 않는다면 이 옵션을 false로 설정하는 것이 scale-down 효율에 무슨 도움이 될지 의문이 들 수 있다.
이 옵션 설정이 효과가 있는 이유는 Istio같은 소프트웨어들에서 emptyDir volume을 다른 용도로 사용하기 때문이다. 로컬 스토리지에 데이터를 저장하기 위한 것이 아니라 RAM 기반의 tmpfs 파일시스템을 사용하거나 이것을 매개로 pod 내의 여러 container들이 서로 데이터를 교환하기 위한 목적이다. 이런 것들은 pod이 실행되는 동안에만 의미가 있기 때문에 노드가 없어져도 데이터가 유실되는 문제가 없다.
경험을 공유하면, scale-down 효율이 떨어지는 클러스터의 CA 로그를 확인해 봤더니 로컬 스토리지 문제 때문에 많은 노드를 scale-down 대상에서 제외한 경우가 있었다. 해당 pod들을 확인하니 Istiod, Istio에 포함된 Prometheus, Redis, SonarQube에 포함된 PostgreSQL이 위에서 설명한 용도로 emptyDir volume을 사용하고 있었다.
아래는 Istiod pod 설정에서 발췌한 것이다.
1apiVersion: v1
2kind: Pod
3metadata:
4 ...
5 name: istiod-1-10-4-6c66f78678-7wl5r
6 namespace: istio-system
7spec:
8 ...
9 containers:
10 - name: discovery
11 ...
12 volumeMounts:
13 - mountPath: /var/run/secrets/istio-dns
14 name: local-certs
15 ...
16 volumes:
17 - emptyDir:
18 medium: Memory
19 name: local-certs
emptyDir.medium: Memory 로 설정하고 있으니 RAM 기반의 tmpfs 파일 시스템을 사용하기 위한 것이다.2
2. CA의 –scale-down-utilization-threshold 옵션 값을 더 크게 설정.
Helm chart를 설치할 때 values.yaml을 아래처럼 설정하면 된다.
1extraArgs:
2 scale-down-utilization-threshold: 0.6 # 디폴트는 0.5. 배포 속도를 고려해 적당한 값으로 설정
디폴트 값은 0.5다. CA가 리소스 활용률이 낮은 노드를 판단하는 기준이다. 노드의 CPU, 메모리 리소스 활용률 중 더 큰 값이 이 설정보다 작으면 scale-down 대상이 된다. 따라서 이 수치를 높이면 대상이 늘어날 수 있다. 하지만 너무 높게 설정하면 pod의 scale-out 이나 배포 속도가 느려질 수 있다. 새로 생성된 pod이 들어갈 공간이 기존 노드에 없어서 새로운 노드를 생성해야 할 확률이 높아지기 때문이다. 실서비스 환경이 아니라면 더 과감하게 올려볼 수 있다.
3. PodDisruptionBudget(PDB) 설정이 scale-down을 막고 있는 상태 해소
잘못 설정된 PodDisruptionBudget이 scale-down을 막을 수 있다.
PDB의 개념이 아직 생소하다면 아래 문서를 통해 개념을 정확히 이해할 필요가 있다. 서비스 안정성이나 클러스터 관리 작업에 많은 영향을 주는 중요한 요소이기 때문에 application 개발자와 클러스터 관리자 모두 개념을 정확히 알고 있어야 한다.
- https://kubernetes.io/docs/concepts/workloads/pods/disruptions/#pod-disruption-budgets
- https://kubernetes.io/docs/tasks/run-application/configure-pdb/
예를 들어, 개발 환경에선 application 당 pod을 1개만 실행하면서 실서비스 환경의 PDB 설정을 그대로 사용하면 문제가 된다. 아래처럼 minAvailable을 30% 로 설정하면 1개만 있는 pod을 종료할 수 없다.
1apiVersion: policy/v1beta1
2kind: PodDisruptionBudget
3metadata:
4 name: demo
5spec:
6 minAvailable: 30%
7 selector:
8 matchLabels:
9 app: demo
이런 경우 minAvailable을 0으로 설정하든지 pod 개수를 2개 이상으로 늘려야 한다. 비용이 더 들겠지만 후자가 적절한 방법이라고 생각한다. 개발 환경이 실서비스 환경과 구조적으로 동일해야 개발 환경에서 미리 여러가지 검증을 할 수 있기 때문이다.
4. kube-system namespace 에서 실행되는 pod에 PodDisruptionBudget 설정
CA는 kube-system namespace에 속하는 pod이 실행되는 노드를 scale-down 대상에서 제외하지만 PDB로 명시적으로 허용하면 대상에 포함한다.
AWS EKS 클러스터라면 아래처럼 CoreDNS에 PDB 설정을 할 수 있다.
1$ kubectl create poddisruptionbudget coredns --namespace=kube-system --selector eks.amazonaws.com/component=coredns --max-unavailable 1
-
만약 어쩔 수 없이 로컬 스토리지를 써야하고 노드 종료를 막아야 하는 상황이 있다면 --skip-nodes-with-local-storage 옵션을 true로 설정하는 것 대신 PodDistruptionBudget을 적절히 설정해 주거나 pod의 annotation에
"cluster-autoscaler.kubernetes.io/safe-to-evict": "false"를 붙이는 방법이 있다.하지만 노드가 다른 이유로 셧다운될 때 데이터를 잃어버리는 것은 마찬가지다. ↩︎ -
emptyDir.medium 이 Memory인 경우는 로컬 스토리지를 사용하지 것으로 보지 않는 것이 합리적일 것 같은데 CA는 emptyDir은 모두 로컬 스토리지 사용으로 본다. 이것은 의도된 동작이라고 한다. --skip-nodes-with-local-storage 옵션이 true일 때 로컬 스토리지를 사용하는 pod을 scale-down 대상에 포함시키려면 pod에
"cluster-autoscaler.kubernetes.io/safe-to-evict": "true"라고 annotation을 붙이면 된다. ↩︎